
Functional-ish JavaScript
Functional programming is a great discipline to learn and apply when writing JavaScript. Writing stateless, idempotent, side-effect free code really does solve a lot of problems:
- It’s easier to test
- It’s easier to debug
- It’s easier to reproduce issues
But there’s a growing impression in the community that functional programming is an all-or-nothing practice. It’s common to hear:
My entire codebase/app is stateful and full of side effects, so why bother trying to make it functional?
I don’t have time to learn what functors, monads or currying are, but I’ll get round to it eventually. Maybe then I’ll start writing functional code.
I prefer writing classes and object oriented code, so functional programming is not for me.
But functional programming does not need to be all-or-nothing, and in my view it’s better to be a little more pragmatic. That is to say, if you don’t do anything else, try writing code that’s functional-ish.
What does that mean? I’ve come up with a set of principles that I hope illustrates the point.
Be predictable, even if you can’t be pure
A function is functionally ‘pure’ if it has zero side-effects. It takes a set of inputs, and gives an output exactly and precisely based on those inputs, and nothing else. It has no other effects, it consumes no state other than the inputs you directly pass in, it does not modify those inputs, and for any given input, the output is always the same.
Writing pure functions is great when it’s possible to do so. They’re easy to test, easy to document, and easy to refactor.

But if your function can’t be pure (which in reality is a lot of the time) the number one thing you should do is make it predictable:
- If the function needs to trigger some side effects, those effects should always be the same, given the same set of inputs. If different inputs trigger different side-effects, those effects should be very predictable given the parameters that are passed in.
- If the function needs to consume data or state from a different scope (like closure scope, module scope, or global scope), it should be resilient to that state changing over time — or ceasing to exist entirely — based on some future state of the app.
- A function should rarely ever mutate any of the parameters passed to it, if they’re mutable data structures like objects or arrays. Exceptions to this rule may be functions whose specific purpose is to mutate an object in a predictable way; like an
arrayRemovefunction whose side effects are obvious.
If in doubt here, follow the Principle of Least Astonishment for any function you write.
Be conservative about state
Pure functions don’t ever rely on outside state. That is to say: if a variable or a piece of data ever changes inside or outside of your function, and your function relies on that data, your function ain’t pure.
In reality, using some kind of state in your code is unavoidable. That said, the least you can do is consider carefully if whether things needs to be stateful or not.
- Is the data you need something that can be derived, based on some inputs or some existing state you already have? If so, it’s best not to explicitly store it as state.
- Is the data something which is used once and thrown away? If so, don’t persist it in any state or scope that will outlive its usefulness.
- Is it a piece of data you will need later, or something that is expected to change over time over the lifecycle of your app? Now you might have a good reason to store it in state.
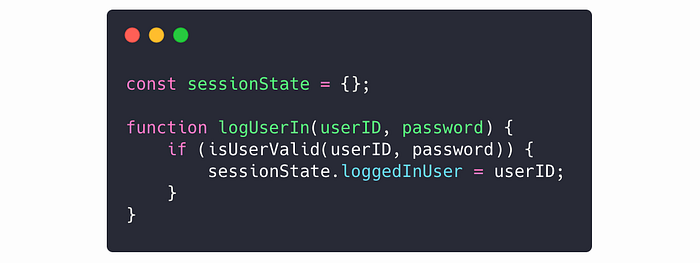
Use scoping to your advantage
Once you’ve decided you actually need some state, you’re not done figuring yet. You know some state needs to exist for longer than the duration of a function call — but you still need to carefully consider how long that state needs to exist for.
You can take advantage of different scopes to make sure your state only sticks around for as long as it needs to:
- If it’s only needed for the current piece of logic, store it in the current block scope using
constorlet. - If it’s needed for the entire duration of the function call, store it in a
letorconstvariable that’s declared at the top level of the function. - If it’s something which needs to exist for a longer time — say, until an asynchronous call completes— store it in closure scope.
- If you’re using React, keep state as close to the component(s) where you need it as possible, and don’t hoist it too high up the component chain.
- If it needs to keep track of something across multiple function calls, persist it in the scope of a parent function, or potentially store it in the module scope.
- If the state needs to persist across multiple pages, store it in a temporary server store — like a session — or in localStorage.
- If it needs to exist for an extended period of time, store it in a database or a filesystem.
Try to pick a scope which keeps your state around for just as long as you absolutely need it for, and no longer.
Encapsulate state
Quite often, stateful data can be encapsulated.
For example, if you have a function which has is expensive to run — either because it takes a lot of cpu cycles, or because it fetches data asynchronously and takes a significant amount of time to return — you have a few options:
- You could manually create a state variable to save the result, and only re-call the function if that variable is not already populated.
- Or, you could abstract away the state in a reusable
memoizefunction:

memoize is a stateful function — we’re keeping a results array around in closure scope for as long as the returned memoized function exists. But in doing so, we’re encapsulating our state in a single place, and ensuring that other functions we want to memoize don’t need to worry about maintaining their own state, and introducing potential new bugs each time.
The thing about state is: all code is ultimately stateful at some level. Even pure functional code written in your language of choice has side effects and state; memory is still being modified, instructions are being sent to the cpu, and the temperature of your computer is increasing.
What’s important is: are those side effects and state changes encapsulated well enough, that they don’t cause state-related bugs in your code? Finding the right level abstraction for your stateful logic — without over-abstracting — is crucial here.
Don’t worry too much about exceptions
Exceptions are typically considered ‘un-functional’ if we’re being strict. Throwing an exception is a side-effect, which can potentially crash the program if it isn’t handled correctly.
In practice though, I prefer to view exceptions as just another kind of return value. Consider the following code:

These are both pure functions. They will only ever return values based on the inputs passed in, and they should never throw any exceptions.
Here’s the same code using exceptions:

This code fulfills the exact same purpose; except now all of the error propagation is implicit and handled by the JavaScript engine.
Yes, in reality the second code snippet might end up crashing my program if the exception isn’t handled. But that can easily be solved with a single try/catch at the entry point to my program, which handles any uncaught exceptions.
The first code snippet is more explicit; but it’s also a lot more verbose, and leaves more room for programmer errors. I have to manually decide at each call point whether to handle an error, or propagate it on to my caller; even though in reality, most of the time I want to propagate.
My preference: treat exceptions as part of the expected result of a function call, and account for the fact that they will be automatically propagated up the call stack. That’s functional-ish enough for me.
Use promises, or async/await, over callbacks
If you haven’t already, I recommend reading the excellent post: Callbacks are imperative, promises are functional.
Promises (and by extension, async/await) allow you to treat asynchronous data as values, rather than as imperative actions. These values can be mapped and combined to form other asynchronous values. For instance:

In each of the steps here, we’re taking an asynchronous value, and mapping it to a different asynchronous value. We don’t especially care about when the data is available; we just care about how one value maps to another.
With callbacks, the emphasis is less about values, and more about “when this task completes, perform this side effect”. So I’d argue they aren’t especially functional-ish.
Promises, on the other hand, can be cached, memoized, passed to other functions as values, and used just like any other value in javascript — with the caveat that they need to be unwrapped before the value can be used.
Yes, promises are stateful. They can be in an unresolved, resolved, or rejected state. But just like in the memoize example, that state is encapsulated to a sufficient degree to allow the rest of your code to be functional-ish.
Use classes, if they fit your purpose
Classes and object-oriented programing are not the diametric opposite to a functional programming style.
To begin with, classes don’t need to be especially stateful at all:

This class is no more stateful than a regular javascript object. Its sole purpose is to tie together some data, with methods that are appropriate for that data. The state doesn’t change over time; making this a very functional-ish class.
Of course, classes can absolutely be used to store state which changes over time. But that by itself is no more or less functional than other stateful patterns.
For example, the following code:

is functionally equivalent to:

The important thing in both examples — and what makes them functional-ish — is:
- How well the state is encapsulated.
- How long the state is kept around for.
- How many side-effects the code has.
Both examples are totally equivalent in that regard (especially with the introduction of private class fields, which hide the state even further).
Use types
This may or may not be a controversial point; but I recommend using Flow or TypeScript when writing JavaScript and writing functional-ish code.
Having clear, self-documented functions, with declared interfaces for parameters and return types, forces you to think in a more functional-ish mindset, and encourages you to write functions which have a clear relationship between the input parameters, and the output value.

On top of that, when you use a static type system, any state in your app will have stricter types, meaning less opportunity for one piece of code to unexpectedly break another, if they’re sharing some common state.

Act immutably, when possible
Whenever it makes sense, update data or state in an immutable way:

This pattern gives a stronger guarantee that you won’t accidentally impact other code or functions consuming the same data as you. That’s especially true if you’re passed a mutable object as an argument; it’s unlikely the caller will expect the object they passed you to change, unless that’s the explicit purpose of your function (which goes back to the ‘be predictable’ principle).
That said, sometimes being immutable means you have to jump through more hoops to propagate data or state to different parts of your app. Often it’s fine to have an object or array or other data structure which is designated as mutable. In these cases, be consistent, be clear, be predictable, and ideally give the object a static type, so it’s clear how it may be mutated and how it may not.
Write functional-ish tests
Regardless of the kind of test you’re writing, be it a unit test, integration test, or end-to-end test, treat everything, absolutely everything, like a function.
Whatever you’re testing — be it a function, or a class, or a React component, or a web app, or anything at all — it will have some inputs, it will have some outputs, and it will potentially have some state.
Your tests should ideally pass in different inputs to the thing you’re testing, and test whether the outputs are what you expect, and nothing more. Never directly test implementation details of what you’re testing, and never directly test the state if there is any — only test the output, and the side-effects.
Ask yourself: Who is the user of the thing you’re testing?
- Is it designed for a developer to integrate? Then your tests should act as if they are that developer.
- Is it designed for an end-user? Then your tests should act as if they’re that end user (as closely as possible).
This way, you’re writing functional-ish tests. You care about the input, and you care about the output, and you don’t care about anything else.
Be pragmatic
Of course, pure functional programming is more predictable, error free, testable, and so on.
But so long as you’re writing real-world code, I’d say it’s good practice to be functional-ish. So long as you’re continually thinking about what side effects you’re triggering, what state you’re creating, and how long that state lives for, you’ll be far more likely to write quality code, even if it isn’t entirely pure.
— Daniel Brain, PayPal Checkout Team
